
SEO
Почему сайта нет в поиске – 10 главных причин

Михаил Петров
19 февр. 2021 г.
Недостаточно просто создать и наполнить сайт, независимо от того, во сколько обошлась разработка, будь то 500 рублей или миллион. Должны быть обеспечены условия, при которых страницы сайта попадут в органическую выдачу поисковых систем. На индексацию и последующее ранжирование ресурса влияют множество факторов, оттого и причины, почему сайта не в поиске, различны. Специалисты digital-агентства «Директ Лайн» подготовили список из 10 главных причин, почему ваш сайт может не отображаться в поиске.
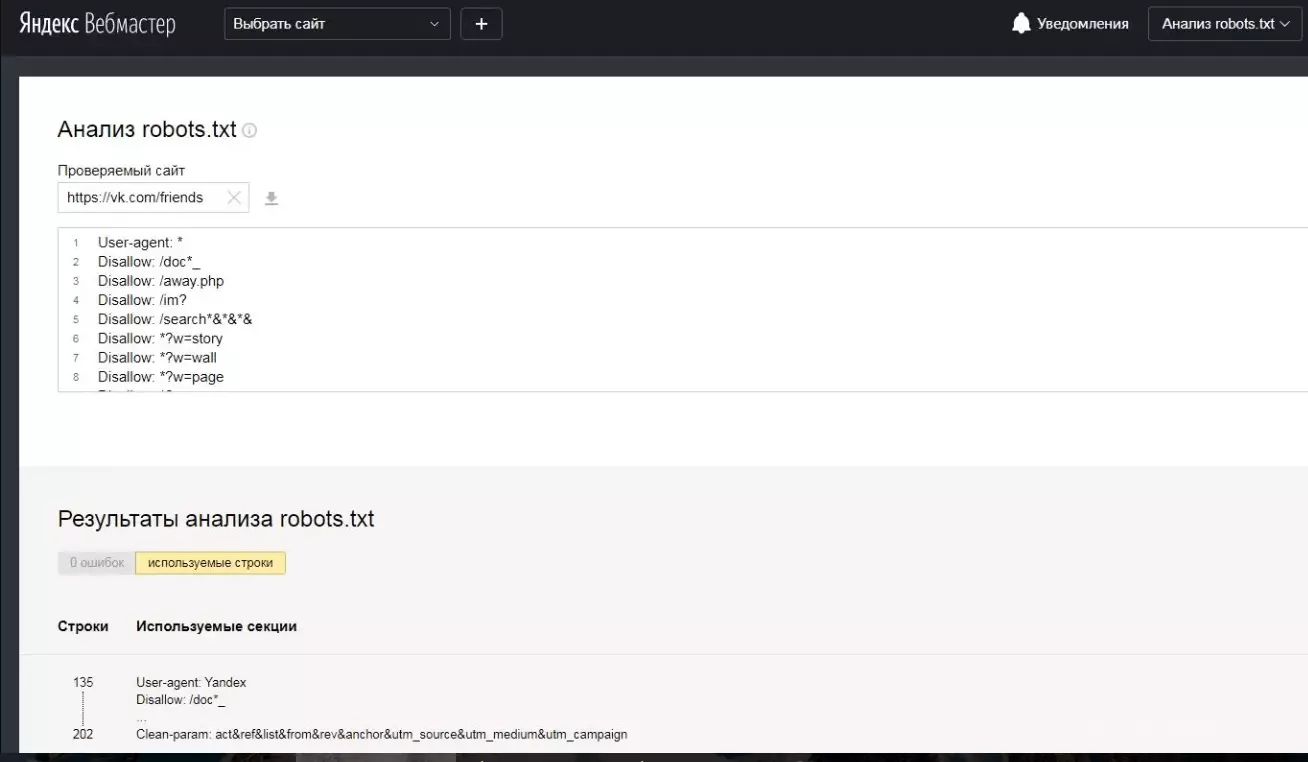
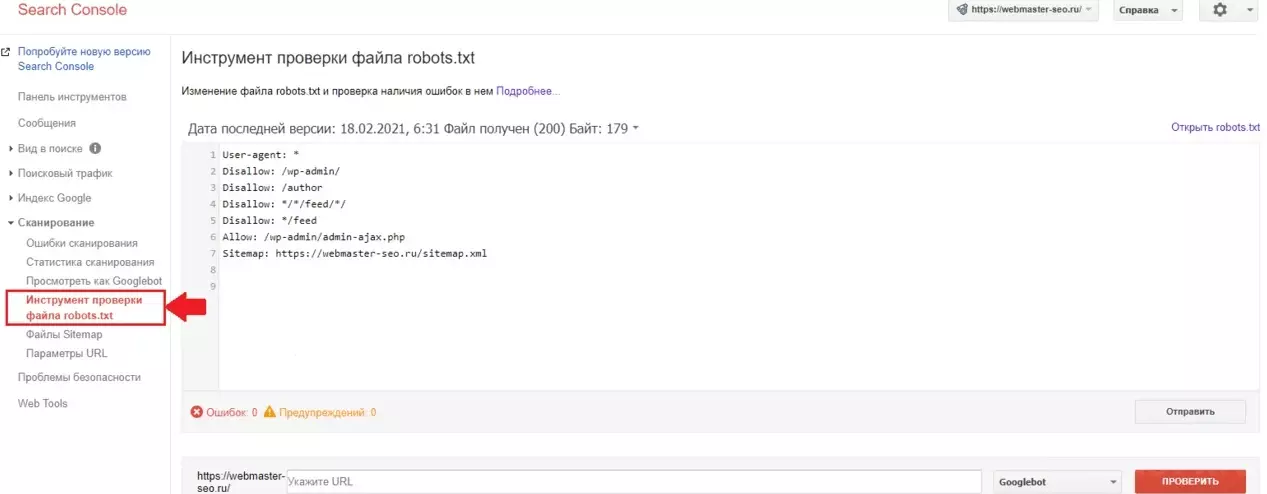
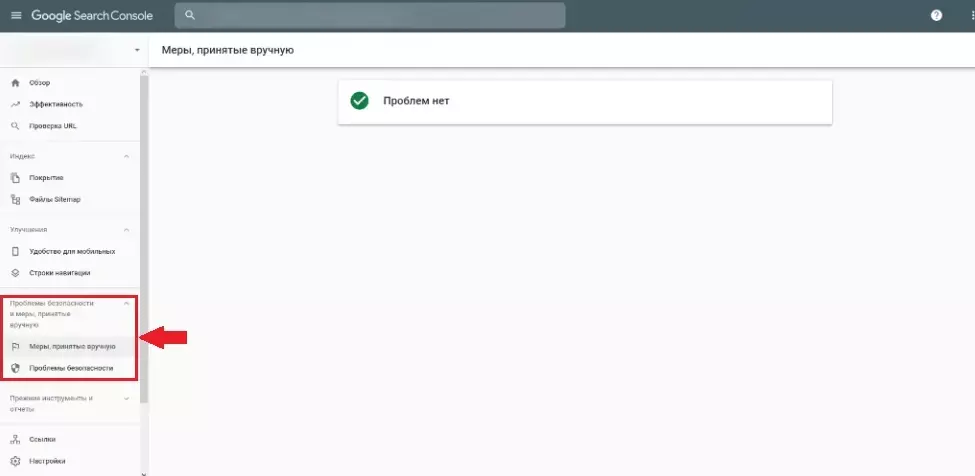
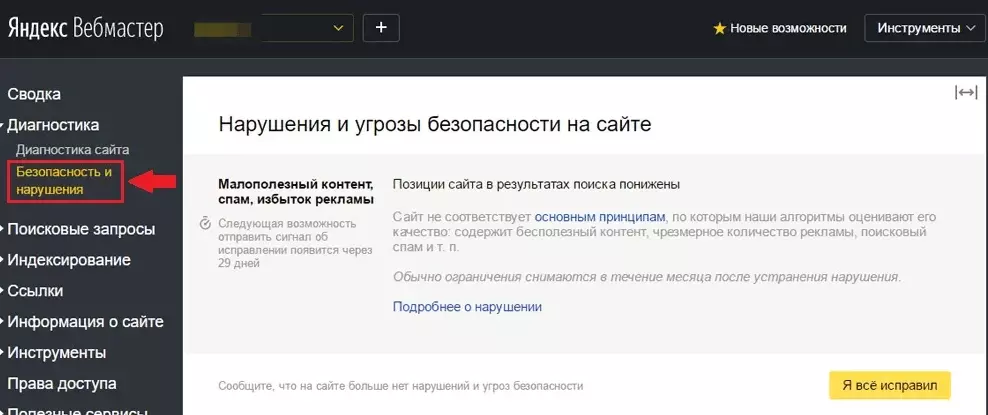
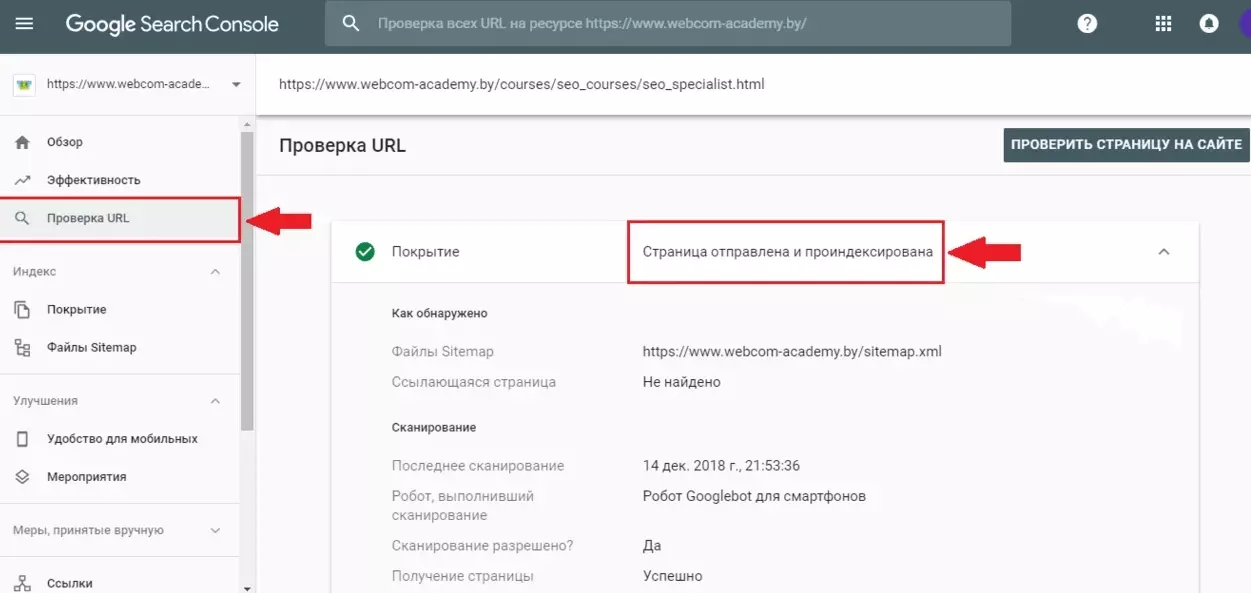
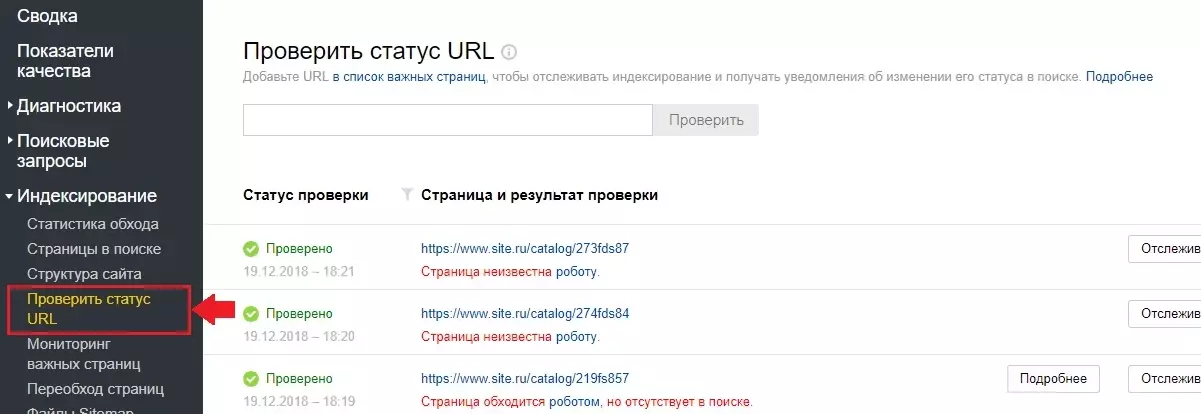

Нужно перепроверить robots.txt
Robots.txt – это текстовый файл, содержащий параметры индексирования сайта для роботов поисковых систем (краулеров). Если допустить в нем ошибку, появится риск неверной передачи нужных команд поисковым роботам. Robots.txt позволяет направлять их на нужные страницы и не пускать на те, которые не нужно индексировать. Если сайт закрыт от индексации, то он и не появится в выдаче поисковой системы. Проверить файл можно в Яндекс.Вебмастере или Google Search Console. Чаще всего, проблемы с индексированием отдельных страниц или разделов сайта, связаны именно с неверным содержимым в Robots.txt.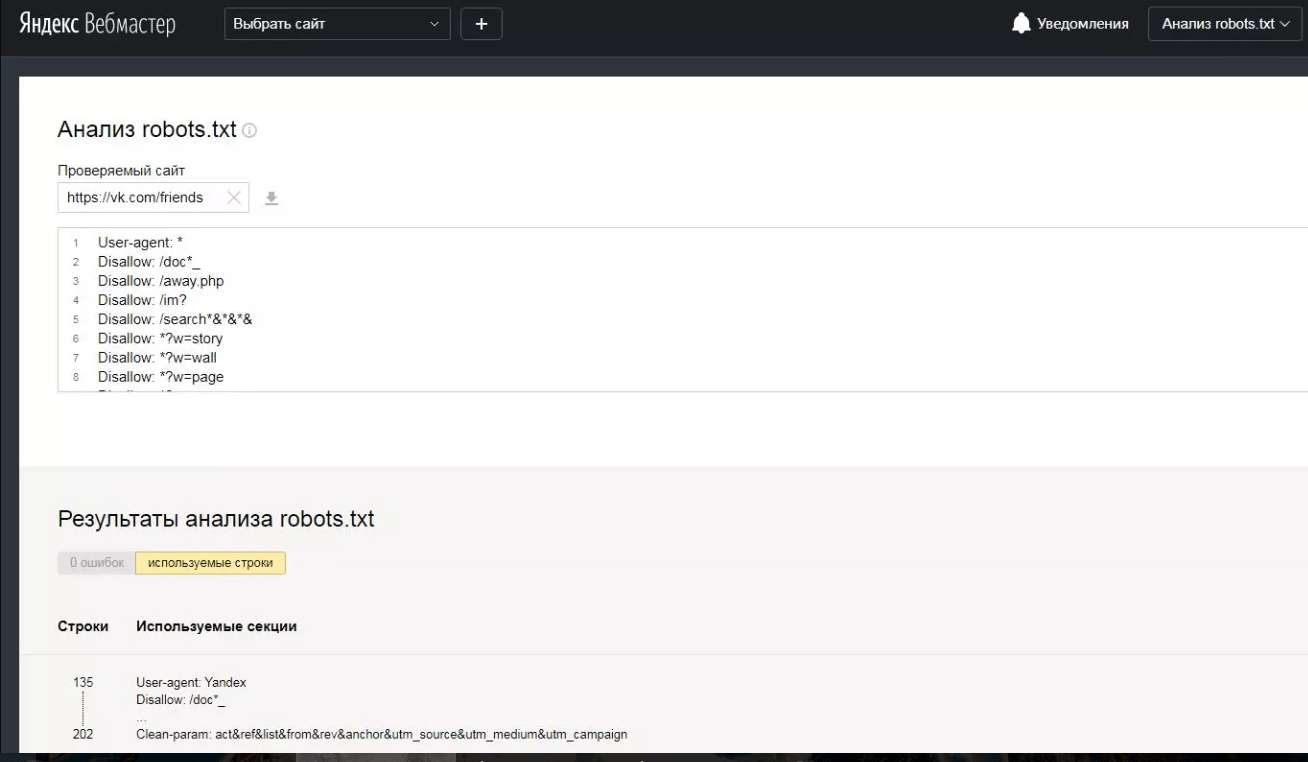
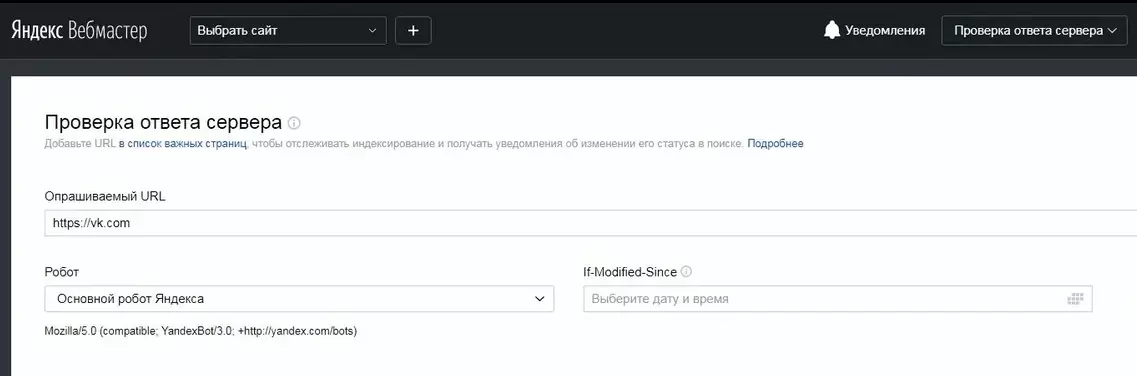
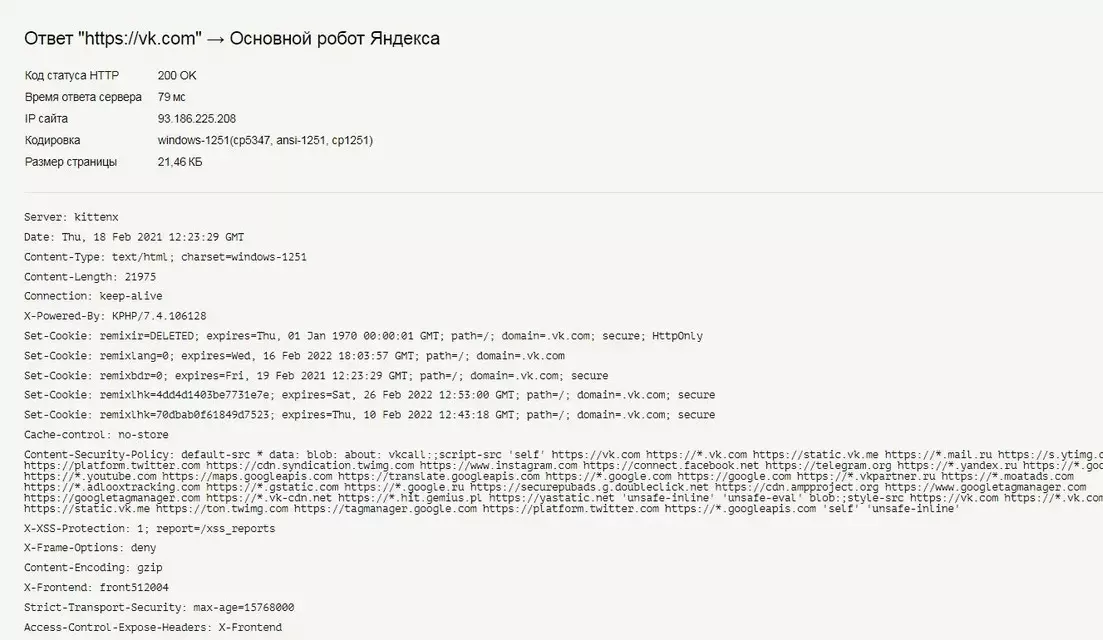
Некорректный ответ сервера
Сайт должен быть доступен и посетителям, и поисковым роботам. Для этого при проверке ответа сервера он должен отдавать код 200 ОК. В противном случае в индекс поисковых систем этот сайт не попадает. Проверить код ответа сервера можно, например, в Яндекс.Вебмастере.
Запрещающие метатеги
Метатеги носят строгий характер для поисковых роботов. Требуется тщательно проверить код страниц на наличие запрещающих метатегов. При необходимости ограничить доступ для краулеров к определённой странице используют meta name="robots". Полный вариант записи: <meta name=“robots” content=“noindex,nofollow”> Важно обратить внимание на возможные значения атрибута content:- noindex, nofollow – запрет индексации всей страницы и переходов по ссылкам на ней;
- noindex, follow – индексация страницы не выполняется, но поисковик может переходить по ссылкам;
- index, nofollow – страница индексируется, но переход по ссылкам запрещен;
- none – альтернатива записи noindex, nofollow;
- noimageindex – запрещает Google индексировать картинки на странице. «Яндексом» не поддерживается;
- nosnippet – указывает поисковым системам не отображать текстовые или видео сниппеты.
HTTP-заголовки X-Robots-Tag
X-Robots-Tag – это заголовок HTTP, дающий указания об индексации сайта поисковым системам. У него есть такие же атрибуты, как и у мета-тега robots. Так, например, если в коде страницы прописано «X-Robots-Tag: noindex», то индексация страницы для поисковых роботов запрещена. Соответственно, необходимо проверить код на наличие подобных конструкций, если сайта нет в поиске.Блокировка в .htaccess
В этом случае необходимо проверить log-файлы сайта и проанализировать, какие роботы посещают страницу. Если внутри файла .htaccess есть строки типа «SetEnvIfNoCase User-Agent "^Googlebot" search_bot», то содержимое скрыто от краулеров. Для разблокировки требуется лишь удалить эти конструкции.Дубли
Наличие страниц-дублей негативно влияет на оценку сайта поисковой системой. Робот вынужден сам выбирать среди нескольких документов наиболее релевантный. При большом количестве страниц-дублей, краулер может вовсе пропустить важные страницы. Не забывайте настраивать тег «rel canonical».Неуникальный контент
Если сайт наполнен материалом, который частично или полностью скопирован с других источников, то поисковая система считает, что он не несет пользы людям. За плагиат сайт или теряет позиции в поиске, или же такие страницы не появляются в поиске вовсе. Разные типы текста имеют определенный порог уникальности. Для проверки текстов используйте любой сервис антиплагиата.Фильтры
Фильтры поисковых систем – это специальные алгоритмы, которые оценивают различные параметры сайта или отдельных его страниц. К таким параметрам относятся качество и уникальность контента, полезность ресурса для пользователей, удобство навигации, наличие нарушений со стороны владельца (например, накрутка поведенческих факторов). Фильтры поисковых систем могут быть ручными и автоматическими. Первые накладываются вручную асессорами или сотрудниками поисковой системы, вторые – самой поисковой системой. Попасть под фильтр – означает потерять позиции или покинуть поисковую выдачу в среднем на 2-3 месяца, пока не будут устранены обнаруженные проблемы. Проверить сайт на наличие основных фильтров можно с помощью «Яндекс.Вебмастер» и Search Console.
Сайт новый
Недавно созданный сайт очень часто не отображается в поиске, так как он просто еще не был проиндексирован. Если ресурс размещается на новом домене, то понадобится в среднем 1-3 недели для его обнаружения поисковыми роботами и старта процесса индексации. В случае использования старого домена, если вы плохо проверили его историю и ранее ресурс негативно воспринимался поисковиками, индексация так же может быть замедлена. Для проверки статуса URL можно воспользоваться сервисами вебмастера Яндекс или Google Search Console.
Сайт виден и доступен, но находится слишком далеко в поисковой выдаче
Часто бывает, что сайт находится далеко за пределами ТОП-50, 100 и т.д. Это может произойти из-за низкой уникальности контента, наличия страниц-дубликатов, переспама ключевыми словами, переполнения рекламой, отсутствия мобильной версии сайта, высокого уровня конкуренции и т.д. Но это уже тема отдельной статьи.Автор статьи
Михаил Петров
Смотрите также

Почему упали позиции сайта в Google
16 ноября 2025 г.
Как получить статистику запросов в Google: обзор инструментов для сбора и анализа частотности
2 декабря 2021 г.
Прописные истины про поисковую оптимизацию и работу с брендом в Интернет
31 августа 2021 г.

Как продвигать сайт в Яндексе самостоятельно
4 февраля 2020 г.
Комментарии(1)
Оставьте комментарий
Войдите, чтобы присоединиться к обсуждению
Полезные рекомендации, даже нечего добавить. Единственное что скажу, даже если с вашим сайтом все в порядке, но позиции слабые, просто улучшайте свой контент, это самая важная составляющая.